
Notes taken from watching "How Git Works" by Paolo Perrotta on Pluralsight
Central Idea – Git is a Map
- Git uses sha1 of every bit of data and then uses that hash as a key for a map of data
git hash-object <file or directory>does exactly this. Orecho "string" | git hash-object --stdin- every object in git has its own SHA1, even commits.
- git doesn’t actually do anything to stop sha1 hash conflicts. Although it is less likely than winning the jackpot 6 times in a row.
- Git is a persistent map, so
git hash-object -wwill also write the file into the repo and use the hash as the key - create .git directory with
git init - rename branch with
git branch -m <new name> - any object saved in git is now in the
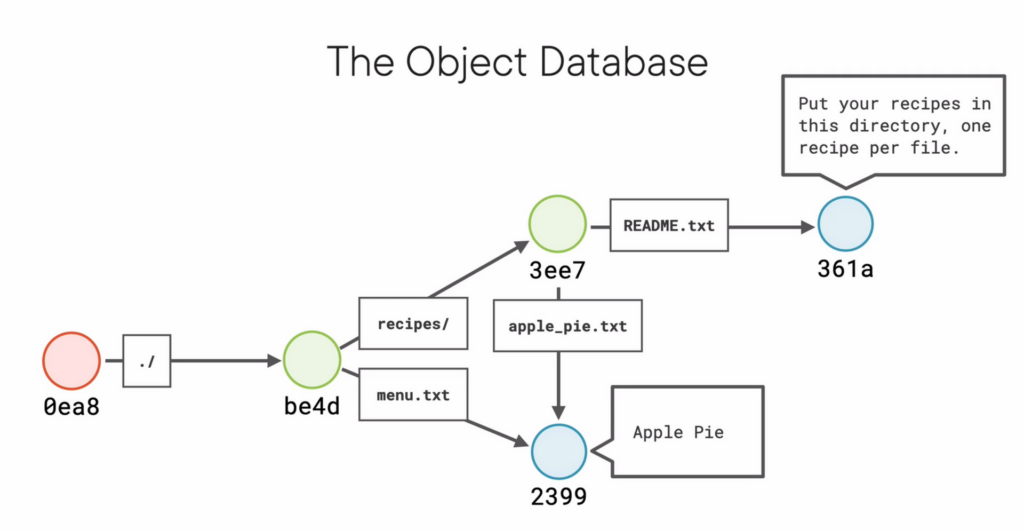
.git/objects/. Ignore theinfoandpackdirectories. The other folders are made up of the first two characters of the SHA1 hash. Each file in there is named the rest of the hash and contains the object itself. It is stored as a blob and has a git header and it compressed, so you can’t just open the file and read it. git cat-file <hash of the file> -pwill show you the original content of the file.-twill show you the type of object
Versioning
git statusshows changes in files and if those changes will be committed (aka, are in the "staging area"). Also which files are untracked, etc.git add <file or dir>will add it to the staging areagit commit -m "commit comment"commits and cleans the staging area.git logshows you all the commits and their hashes.- a commit is added to the object database with its hash.
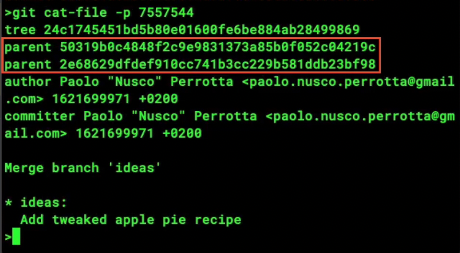
- If you look at a commit object with
git cat-file, it shows the author, committer, date, the commit message, and the hash of a tree (a directory stored in git)

- If you look at a tree object with
git cat-file, it shows a list of hashes for the files in the tree. With type, hash, file name. Another tree in the tree file will simply point you to another directory. Also, the data to the left is just access permissions.

- The reason that a blob is not a file is that files have names and permissions. These are not stored in a blob, but are stated in the tree
- once you make another commit, that commit object keeps track of the parent commit

- in the new commit, there’s an entirely new tree, but the tree will still have the same hash keys for unchanged files. git is efficient because it doesn’t store the same file more than once. (until there’s a change, of course.)
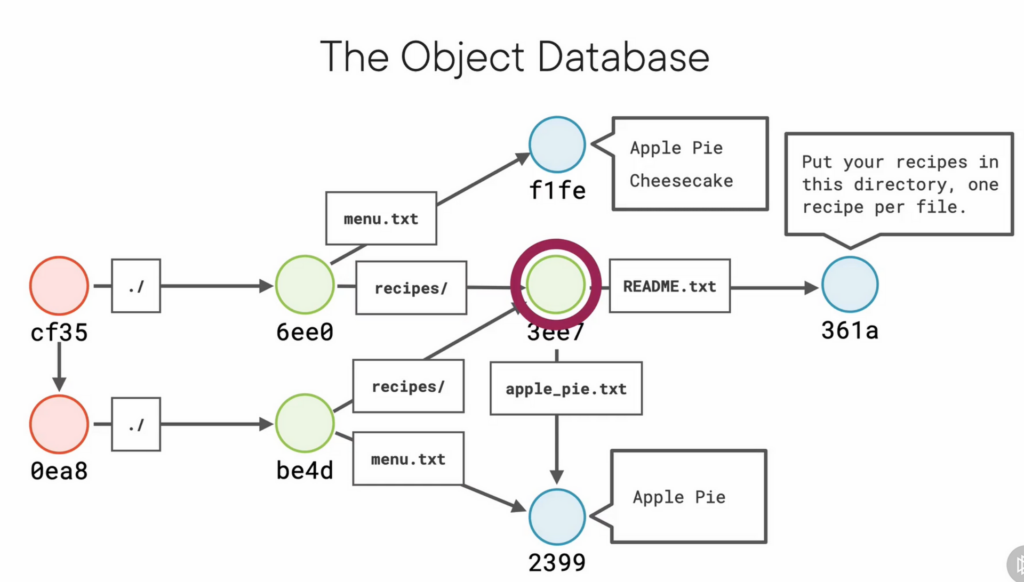
- You can count 8 objects in the above diagram. 2 commits, 3 trees, and three blobs.
git count-objectswill confirm this. - in reality, git is optimized so if you change a single line in a large file, git might only store the changes between the two files instead of storing two nearly identical blobs. This optimization is the reason for
.git/objects/infoand.git/objects/pack - There is a 4th type of object in the git database: an annotated tag, showing data, message, and is attached to a commit.



Branches
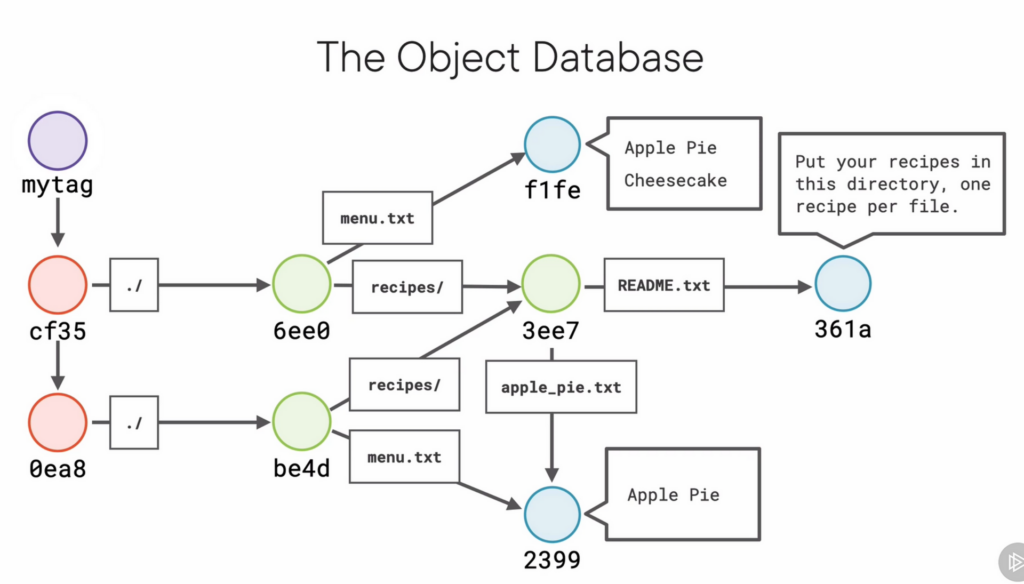
git branchwill show all the possible branches and has an asterisk next to the current branch- a branch is stored in
.git/refs/heads/ - the file of the branch is human-readable and contains a single line – the hash of the current commit. A branch is a reference to a commit
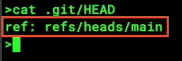
git branch <branch name>to create a new branch. (literally all this does is create a new file in.git/refs/heads/with that name. You could actually delete a branch by just deleting that file)- git knows the current branch because of the
.git/HEADfile. It’s a reference to a branch. A pointer to a pointer, if you will
- When switching branches, git not only changes
.git/HEAD, but also updates the working area with the appropriate files for the given commit.
Merging
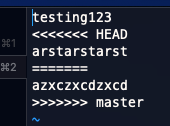
- When merging and a conflict occurs, open the file, and you can see the converged files…
- above
<<<<<< HEADis non-conflicting code - after
<<<<<< HEADand before========is the current branch’s code - after
========and before>>>>>> <other branch name>is the other branch’s code - as soon as the conflict is fixed, the file must be
git added to be staged. This is how git knows to resolve the conflict. You don’t need a commit message for merges; git already knows. - A merge is just like a commit, but with two parents
- Remember that git doesn’t really care about your working directory. It will overwrite it with stuff from the object database with many commands, but it will give you a warning before deleting your progress.
Fast-Forward
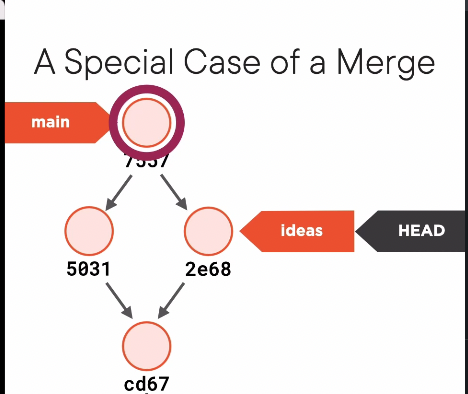
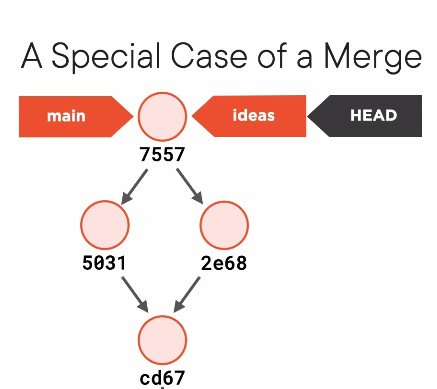
- If you merge with a branch that has already merged with you, it will simply
fast-forwardand put your branch at the same point as the other branch.
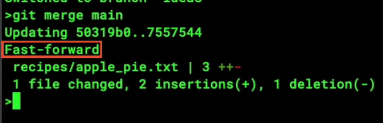
- ^this message is git bragging that it didn’t need to actually do hardly anything.
Detaching the HEAD
- This is useful for when you want to experiment with the code and go down a completely new path to see if an idea would even work. You can still use git to keep track of changes, but your changes are as good as gone when you switch back to your branch if you don’t want them saved.
- You can
git checkouta commit, not a branch! This is called adetached head - Once you
git committhen head is updated to the next commit, functioning as its own branch
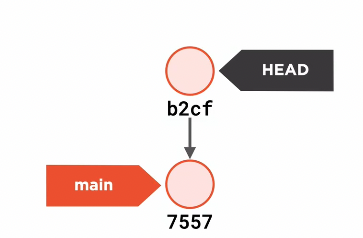
- Once you
git switchback to your branch, the commits that were made without a branch are unreachable without you taking note of their hashes. They are effectively isolated. At some point, because there are no references to these commits, they are garbage collected and deleted.

- To save these commits, move to the latest one and
git branch <branch name>
Rebases
- If you want to combine two branches, you can use
git mergeand get a separate commit, and only your current branch updates to that new commit.
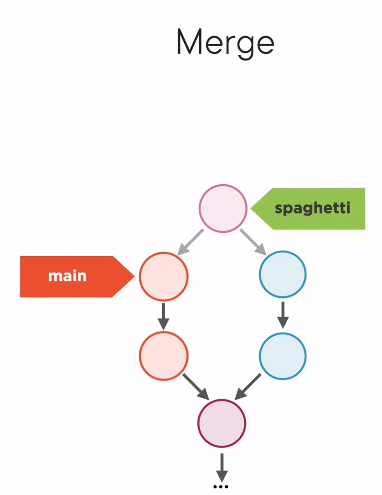
- instead, you could
git rebasethe new branch to add changes ON TOP of the other branch’s latest commit. You get all the commits of the other branch, then all the commits of your current branch after.
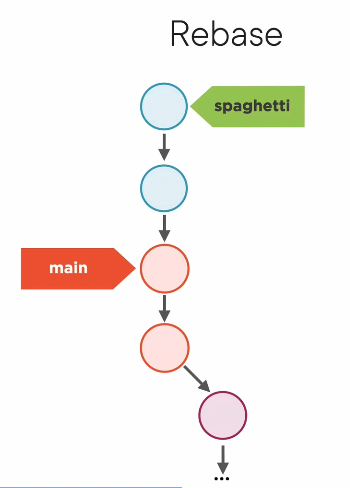
- Rebase can be fast-forwarded, just like merge
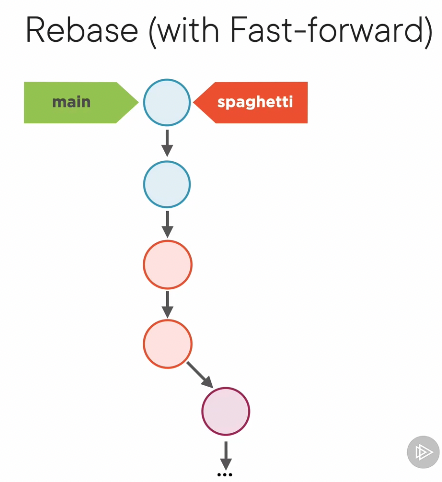
- How this works: Every commit in the branch gets a new parent hash, so the hash of each commit changes. In reality, git makes a copy of the commit, then changes it. Then moves on to the next commit in the line. After all copies are made and moved over, then the branch points at the new commit and the old copies are LEFT. They are then garbage collected later.
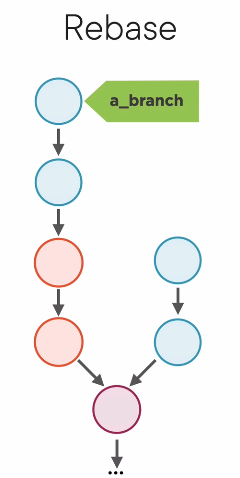
Merge vs Rebase
- Merging preserves history exactly as it happened. merges never lie
- see history with
sourcetreepackage and commandstree - Rebasing helps refactor project history to look nice. But it’s basically deleting commits and creating new ones with non-correct times and timelines.
- Rebasing can cause unwanted effects with certain complex git commands. When in doubt, just merge
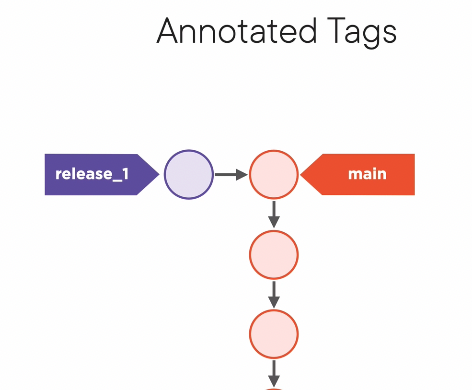
Annotated and Lightweight Tags
- like a label for a commit. so like a branch!
- A tag is different from a branch in that it does not move
git tag <tag string> -a -m "message string"for an annotated tag. the-ameans annotated, and-mmeans message or metadatagit tagwill list tags- Now, you can do
git checkout <tag string>to go to a specific commit despite where the branches may be. (git switch does not work for this) - Under the hood, tags are files stored in
.git/refs/tags/that contain the hash to a tag object. That tag object contains the commit hash, tag name, tagger, and message
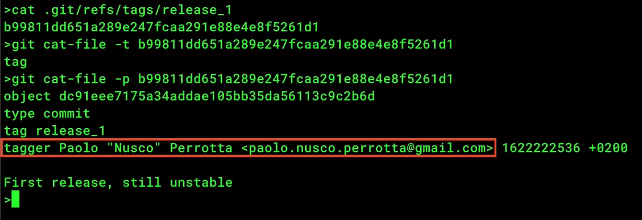
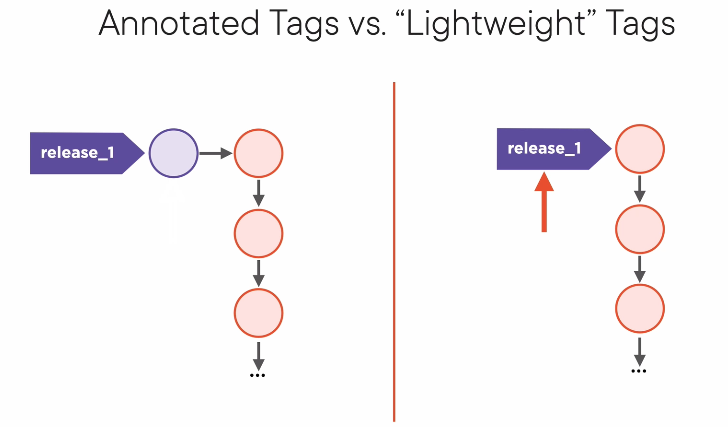
git tag <tag string>for a lightweight tag. This does NOT create a database object, just a file that contains the commit hash.

Distributed Version Control
git clone <url>will get not only the files, but the entire.gitrepo from the cloud. It auto-checks out the master or main branch- The
.git/configfile saves information about other copies of the same repository. These are namedremotecopies.originis the default remote origin
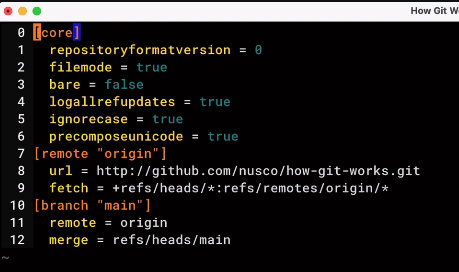
- The branch info here^ matches the name of the local branch with its corresponding branch name in the remote repo. Although these branches are syncing, they could be called different names by editing this file.
- recap:
git branchwill show you all the local branches git branch --allwill show you even the remote branches- These branches are stored in
.git/refs/remote
- These branches are stored in
- Any branches not shown in the
.git/refs/remotefolder are compacted into the.git/packed-refsfile.

git show-ref <branch name>will show you which commit a specific branch is pointing at.

- ^both the local main branch and the remote main branch point to the same commit.
git pushwill simply copy the missing objects from one source to another. It will also update the remote branch!- Now if your remote repo is ahead of your local repo, to push, you have two options…
git push -f(not recommended) force the push. Its like saying "I don’t care whats on the remote repo. Force it to mirror my local repo". You lose any commit that your local machine did not have. These are then garbage collected. This strategy does not solve conflicts, it just forces that conflict on other users.git fetchwill update the remote repo branch on our own computer, likelyorigin/main, but will not update our local branch. After this, you can merge the two branches to see the conflicts.
git fetch+git merge=git pull- Rebases are tricky with a shared repo, because if you rebase, then fetch, then merge, you end up in the very same position you started in, but with two identical commits in the history (the original commit, its rebased copy, then the new commit created the merge whose parents are the first two of these three)
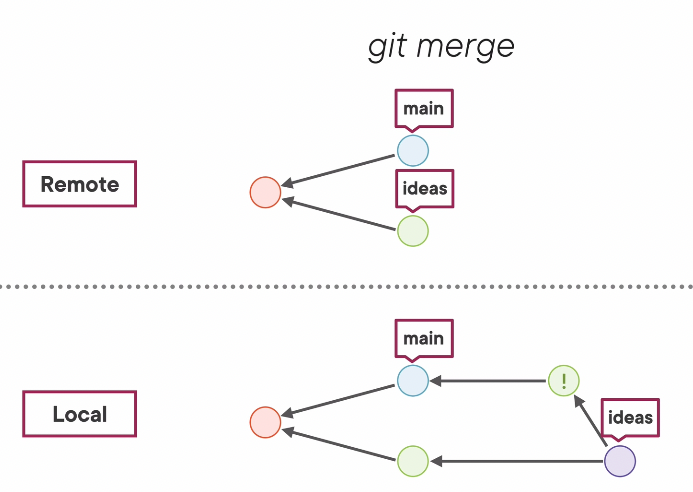
- Because of this, DON’T REBASE SHARED COMMITS. If the commit is already pushed, don’t rebase it.
GitHub/GitLab Features to Know
Forks
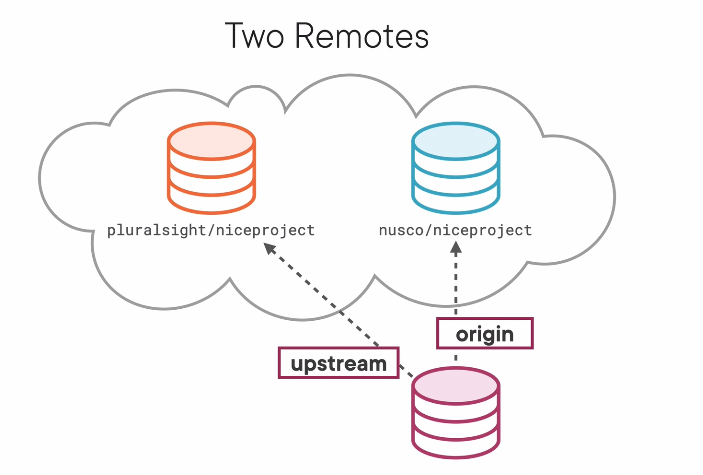
- We can create our own copy of a project from someone else’s GitHub account and putting it into our own GitHub cloud account with GitHub’s "Fork" button. Git does not know the connection between the two repos, but GitHub does.
- You clone your own copy so you can edit it
- You can then use
.git/configto set another remote repo so you can get changes from the original author.
Pull Requests
- If you want the original author to use your changes, you cannot push upstream, but you can submit a pull request message to them in GitHub.


