
I’ve put too many hours into perfecting my bare-metal Kubernetes home lab. To automate the process, I’ve developed scripts, tricks, and found tools to help me build a fully working cluster quickly. So let me show you how I set up my home lab cluster.
I’ve streamlined my process for installing Kubernetes, and with some handy add-ons!
MetalLB(load balancer that can utlilize unused IPs in the cluster’s network)KubeVIP(virtual ip address to create a highly available cluster)Traefik Ingress Controller(controls TLS routes to services and applications)Traefik Middlewares(network add-ons to provide customization to network routes)Traefik Dashboard(graphical UI for network statistics, router, plugin statuses, etc)Cert-Manager(automated deployment and renewal of TLS certificates)Rancher(graphical UI for managing kubernetes)Longhorn(distributed block storage engine)Argo-CD(continuous deployment UI for installing apps usinghelm, the Kubernetes package manager)Portainer(graphical UI for managing kubernetes)Kubernetes Dashboard(graphical UI for managing kubernetes)Rancher Backups(for automating backups/restores of Rancher’s data)Graphana + Prometheus(metrics monitoring and visualization)CloudCasa Backups(backup solution for both config files (always free) and persistant volumes (free up to 100GB of S3 storage/month)
I’ll be setting up my cluster with 3 master and 5 worker pods. I’ll utilize two different services to create virtual IPs on my network as well.
- Kube – 10.0.0.200 (virtual IP for master nodes to share)
- Kube1 – 10.0.0.201 (master 1)
- Kube2 – 10.0.0.202 (master 2)
- Kube3 – 10.0.0.203 (master 3)
- Kube4 – 10.0.0.204 (worker 1)
- Kube5 – 10.0.0.205 (worker 2)
- Kube6 – 10.0.0.206 (worker 3)
- Kube7 – 10.0.0.207 (worker 4)
- Kube8 – 10.0.0.208 (worker 5)
- MetalLB – 10.0.0.210-10.0.0.249 (virtual IP range for load balancing applications)
Prerequisites
- You’ll need some programs installed on your local PC for this tutorial
kubectlkubenskubectxk3suparkadehelm
- A domain name with it pointed at your public IP address
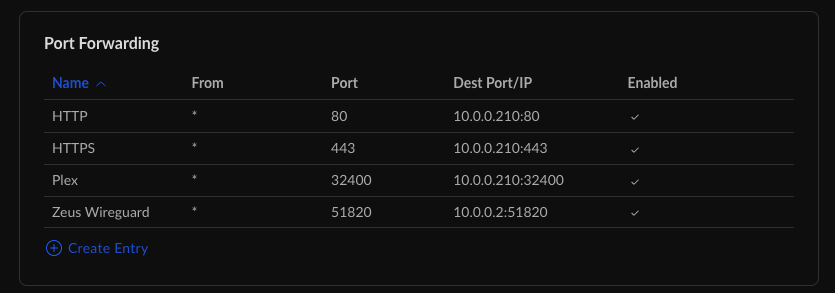
- The ability to port-forward ports 80 and 443 to your cluster
Instruction Note
In my instructions, my username is line6 – change this to be yours
In my instructions, my network’s internal domain is .lan. Yours may & can be different. Usually .local is standard. So when I want to ping a computer with hostname kube4, the fully qualified domain name is kube4.lan.
This tutorial is strictly how I, myself, set up my cluster. It’s sprinkled with steps that maybe only I will need. Feel free to skip steps after the initial install if something doesn’t fit your needs.
With that out of the way, lets set up a cluster!

Node Preparation
BIOS Settings
- Disable secure boot
- Update BIOS
- Perform memory check
- Perform extensive hard drive check
Install your operating system. I’m using Ubuntu 22.04.2 LTS.
- Give it an easy to remember static IP upon installation.
- I use
10.0.0.201forkube1,10.0.0.202forkube2, etc.
Once booted, copy your ssh key onto each machine
ssh-copy-id <username>@<ip>Ensure each node is fully up to date.
sudo apt update && sudo apt upgrade -yAdd your DNS records to your DNS server if possible. For example, I wanted my first node (10.0.0.201), to be called kube1 so that I didn’t need to remember the IP, I could just ssh or ping kube1 instead.
Set the root password on the node
sudo su
passwdOptional: edit the sudors file so your user (not root) can run sudo without needing to enter a password.
sudo visudoEdit the line that begins with %sudo, adding NOPASSWD: ALL to the end.
%sudo ALL=(ALL:ALL) NOPASSWD:ALLSave and exit
Set timezone (edit to be your timezone)
sudo timedatectl set-timezone America/DenverDisable swap
sudo swapoff -a
sudo sed -i '/ swap / s/^\(.*\)$/#\1/g' /etc/fstabInstall & enable some packages you may need
sudo apt-get install bash curl grep nfs-common open-iscsi jq apparmor apparmor-utils iperf -y
sudo systemctl enable --now open-iscsi
sudo systemctl enable --now iscsidBlacklist longhorn devices from a service called multipathd
sudo vim /etc/multipath.confAdd the following text into the bottom of the file
blacklist {
devnode "^sd[a-z0-9]+"
}Save and exit the file. Then restart the multipathd service
systemctl restart multipathd.serviceReboot the computer
rebootCreate Cluster
For every command from here on out, you’ll run on your local computer, not a node, unless otherwise specified.
Run setup script
This script will…
- Use a tool called
k3supto installk3sonto each of the nodes remotely - Intentionally install
k3swithout a load balancer or traefik installed - Install
metallband test it, opening browser window to view annginxtest deployment - Install
cert manager - Install
traefikand print out the IP you should port forward to
While editing the variables in this script, keep a few things in mind…
- Remember that I have 3 masters, so I’m going to use a service called
kubevipthat will make a shared IP between the 3 master nodes. This way, if one master goes down (or if the masters switch roles) the IP address to reach the active master node will be the same. I’ve chosen10.0.0.200to be this virtual IP address. This is important because when you installk3s, you can set TLS parameters for an IP or hostname, and I want my master node to have TLS at the virtual IP address (10.0.0.200) and the hostnamekube. - At the time of writing this,
k3sversionv1.26.7-rc1+k3s1is the latest version that Rancher supports, so I’ll install k3s with that version.
On your local PC, tweak the values of this script and run it to create the cluster
#!/bin/bash
rm ~/.kube/config # comment this out if you have more than one cluster
# ____________________ EDIT VARIABLES __________________________
export NODES=(
"kube1" # "10.0.0.201"
"kube2" # "10.0.0.202"
"kube3" # "10.0.0.203"
"kube4" # "10.0.0.204"
"kube5" # "10.0.0.205"
"kube6" # "10.0.0.206"
"kube7" # "10.0.0.207"
"kube8" # "10.0.0.208"
) # In this script you can replace --host and --server-host with --ip and --server-ip if you don't have DNS names
export USER="line6"
export CLUSTER_NAME="kubernetes_cluster"
export K3SVer="v1.26.7-rc1+k3s1"
export VIPIP="10.0.0.200" # Virtual IP address that the master nodes will share
export VIPHostname="kube"
export NETWORKSuffix="lan"
export EXTRAArgs="--disable traefik --disable servicelb"
export MetalLB_IPRange="10.0.0.210-10.0.0.249" # Range for MetalLB to use
# _______________________ END OF VARIABLES ______________________
GREEN='\033[32m'
RED='\033[0;31m'
ENDCOLOR='\033[0m'
for index in "${!NODES[@]}"; do
echo -e "${GREEN}------- Installing on ${NODES[$index]} -------${ENDCOLOR}"
# The first server starts the cluster
if [[ $index -eq 0 ]]; then
k3sup install \
--cluster \
--user $USER \
--host ${NODES[$index]} \
--k3s-version $K3SVer \
--local-path $HOME/.kube/config \
--context $CLUSTER_NAME \
--merge \
--tls-san $VIPIP --tls-san $VIPHostname --tls-san $VIPHostname.$NETWORKSuffix \
--k3s-extra-args "${EXTRAArgs}"
elif [[ $index -eq 1 || $index -eq 2 ]]; then
# The second and third nodes join as master nodes
k3sup join \
--server \
--host ${NODES[$index]} \
--user $USER \
--server-user $USER \
--server-host ${NODES[0]} \
--k3s-version $K3SVer \
--k3s-extra-args "${EXTRAArgs}"
else
# The rest of the nodes join as worker nodes
k3sup join \
--host ${NODES[$index]} \
--server-user $USER \
--server-host ${NODES[0]} \
--user $USER \
--k3s-version $K3SVer
fi
done
echo -e "${GREEN}------- k3s installed, moving to backend apps -------${ENDCOLOR}"
# MetalLB Installation
echo -e "${GREEN}------- Installing MetalLB Load Balancer -------${ENDCOLOR}"
kubectl apply -f https://raw.githubusercontent.com/metallb/metallb/v0.10.3/manifests/namespace.yaml
kubectl apply -f https://raw.githubusercontent.com/metallb/metallb/v0.10.3/manifests/metallb.yaml
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: ConfigMap
metadata:
namespace: metallb-system
name: config
data:
config: |
address-pools:
- name: default
protocol: layer2
addresses:
- $MetalLB_IPRange
EOF
# Traefik Installation
echo -e "${GREEN}------- Installing Traefik Ingress Controller -------${ENDCOLOR}"
helm repo add traefik https://traefik.github.io/charts
helm repo update
# create values.yaml for traefik. Need this to be "local" so that X-Forwarded-For headers are transmitted
echo "\
additionalArguments:
- '--serversTransport.insecureSkipVerify=true'
service:
spec:
externalTrafficPolicy: Local
" > /tmp/traefik-values.yaml
helm upgrade --install traefik traefik/traefik --create-namespace --namespace traefik --values /tmp/traefik-values.yaml
cat <<EOF | kubectl apply -f -
apiVersion: traefik.io/v1alpha1
kind: IngressRoute
metadata:
name: dashboard
namespace: traefik
spec:
entryPoints:
- web
routes:
- match: Host('traefik.localhost') && (PathPrefix('/dashboard') || PathPrefix('/api'))
kind: Rule
services:
- name: api@internal
kind: TraefikService
EOF
# Cert-Manager Installation
echo -e "${GREEN}------- Installing Cert Manager -------${ENDCOLOR}"
helm repo add jetstack https://charts.jetstack.io
helm repo update
helm upgrade --install cert-manager jetstack/cert-manager --namespace cert-manager --create-namespace --set installCRDs=true
# Test out external IP address assignment with MetalLB
sleep 10
echo -e "${GREEN}------- Testing out MetalLB Load Balancer -------${ENDCOLOR}"
kubens default
kubectl create deploy nginx --image=nginx
sleep 5
kubectl expose deploy nginx --port=80 --target-port=80 --type=LoadBalancer
sleep 20
external_ip=$(kubectl get service nginx -o jsonpath='{.status.loadBalancer.ingress[0].ip}')
if [[ -n "$external_ip" ]]; then
echo -e "External IP: $external_ip"
if command -v open &> /dev/null; then
open "http://${external_ip}:80"
elif command -v xdg-open &> /dev/null; then
xdg-open "http://${external_ip}:80"
elif command -v google-chrome &> /dev/null; then
google-chrome "http://${external_ip}:80"
else
echo -e "${RED}Failed to open web browser. Please manually open a web browser and navigate to http://${external_ip}:80.${ENDCOLOR}"
fi
else
echo -e "${RED}LoadBalancer is still pending, may not be functional yet${ENDCOLOR}"
fi
# Print Traefik External IP
echo -e "${GREEN}------- Print Traefik Ingress Point -------${ENDCOLOR}"
kubectl get svc -n traefik
external_ip=$(kubectl get service traefik -n traefik -o jsonpath='{.status.loadBalancer.ingress[0].ip}')
echo -e "\nOn your router, ${GREEN}Port forward${ENDCOLOR} ports 80 and 443 to ${GREEN}$external_ip${ENDCOLOR}"
echo -e "\n${GREEN}------- Setup Complete -------${ENDCOLOR}\n"To run this, you’ll have to make the file executable
chmod +x k3sup-script.sh
./k3sup-script.shYou can run this script multiple times if any nodes have issues and you need to try again. A full uninstall of k3s shouldn’t be necessary most times.
Once the script is done, you can verify that all pods are connected to the cluster by running
kubectl get nodesThis may spit out TLS errors (for now), but it should also give us what we’re looking for…
NAME STATUS ROLES AGE VERSION
kube1 Ready control-plane,etcd,master 32m v1.24.11+k3s1
kube2 Ready control-plane,etcd,master 32m v1.24.11+k3s1
kube3 Ready control-plane,etcd,master 21m v1.24.11+k3s1
kube4 Ready <none> 23m v1.24.11+k3s1
kube5 Ready <none> 23m v1.24.11+k3s1
kube6 Ready <none> 23m v1.24.11+k3s1
kube7 Ready <none> 23m v1.24.11+k3s1
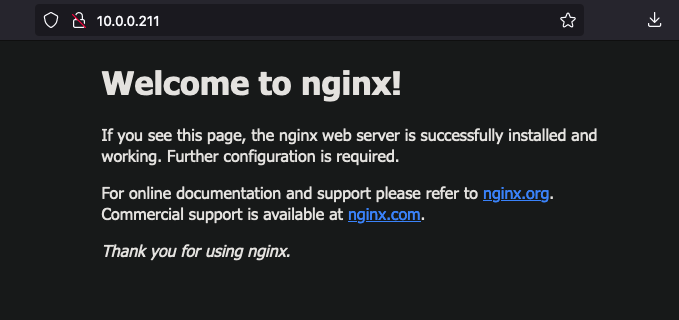
kube8 Ready <none> 23m v1.24.11+k3s1This script, if the variables are correct, should also open a browser window to view an nginx deployment. Verify that this worked. (TLS is not enabled so your browser may complain)
For me, this usually shows up on 10.0.0.211, the second available ip in the metallb address space of 10.0.0.210-10.0.0.249.
The first ip available to metallb is 10.0.0.210, which was used to set up traefik. The end of the script should show you which IP the traefik load balancer is using.
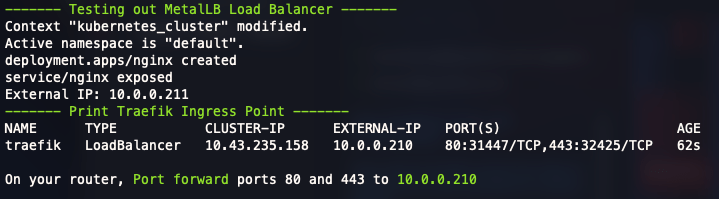
Do like the script says and port-forward to this IP.
If something horribly wrong happens in your setup script, you can remove k3s and start over. I created a script for this that I’ll put at the end of this post.
Optional: Tagging Kubernetes Nodes
You can tag nodes however you like and perform logic on them later so that the cluster can make smart decisions about where a pod or Persistent Volume should go.
I label mine as such:
# role
kubectl label nodes kube1 kube2 kube3 role=master
kubectl label nodes kube4 kube5 kube6 kube7 kube8 role=worker
# ram-size
kubectl label nodes kube1 kube2 kube3 kube4 ram-size=medium
kubectl label nodes kube5 kube6 kube7 kube8 ram-size=large
# disk-size
kubectl label nodes kube1 kube2 kube3 kube4 kube5 disk-size=medium
kubectl label nodes kube6 kube7 kube8 disk-size=large
# extras (for nodeAffinity settings, if desired. This is an example)
kubectl label nodes kube8 plex-server=true
kubectl label nodes kube1 kube2 kube3 kube4 kube5 kube6 kube7 plex-worker=trueSet up KubeVIP
Kube-vip is a lightweight solution that provides Kubernetes Virtual IP and Load-Balancer for both control plane and Kubernetes services. We’ll use KubeVIP as a way to always be able to communicate with an active master node. This way, we can have one IP (10.0.0.200) that can be used by all three masters. And if any one or two of them go down, we can still communicate with the one that is up without needing to change the IP address in our kubeconfig file.
Login as root into the first k3s node and apply RBAC settings for kube-vip.
ssh line6@kube1
sudo su
curl -s https://kube-vip.io/manifests/rbac.yaml > /var/lib/rancher/k3s/server/manifests/kube-vip-rbac.yamlFetch the kube-vip container, create an kube-vip alias and generate a kube-vip manifest which will deploy a daemonset
ctr image pull docker.io/plndr/kube-vip:0.3.2
alias kube-vip="ctr run --rm --net-host docker.io/plndr/kube-vip:0.3.2 vip /kube-vip"
export VIP=10.0.0.200 # virtual IP address for master nodes
export INTERFACE=eno1 # check your interface on the node and use the main one!
kube-vip manifest daemonset --arp --interface $INTERFACE --address $VIP --controlplane --leaderElection --taint --inCluster | sudo tee /var/lib/rancher/k3s/server/manifests/kube-vip.yamlEdit the kube-vip.yaml file
sudo vim /var/lib/rancher/k3s/server/manifests/kube-vip.yamlAdd the line in bold
tolerations:
- effect: NoSchedule
key: node-role.kubernetes.io/master
operator: ExistsSave and exit editing the file.
Go back to your local computer
Now, your master node should be reachable on the virtual IP
❯ ping 10.0.0.200
PING 10.0.0.200 (10.0.0.200): 56 data bytes
64 bytes from 10.0.0.200: icmp_seq=0 ttl=63 time=6.128 ms
64 bytes from 10.0.0.200: icmp_seq=1 ttl=63 time=3.057 ms
64 bytes from 10.0.0.200: icmp_seq=2 ttl=63 time=5.288 msNOTE: I’ve made the DNS record of Kube.lan point to the virtual address 10.0.0.200, so they’ll be interchangable from here on out.
Edit your kubeconfig file to point to the virtual IP address so you’ll always be able to reach a master node.
vim ~/.kube/configReplace the IP or hostname of your master node with the IP or hostname of the virtual IP
server: https://kube1.lan:6443
# should now be
server: https://kube.lan:6443Save and exit the file
Ensure your kubeconfig file works and you can connect to the virtual IP
kubectl get nodesNow, there should be no TLS errors
Traefik Middlewares
Whitelist Middleware
Before we get too far into port-forwarding, DNS records, and publishing websites, we should create few quick methodsto ensure that our websites aren’t external to the world.
We’ll deploy a middleware for Traefik titled ipWhiteList. This way, we can set a simple annotation on any ingress and it will then only be accessible from inside our home network.
cat <<EOF | kubectl apply -f -
apiVersion: traefik.io/v1alpha1
kind: Middleware
metadata:
name: internal-whitelist
namespace: traefik
spec:
ipWhiteList:
sourceRange:
- 10.0.0.0/24 # replace with your internal network range
ipStrategy:
excludedIPs: []
EOFFor future ingresses, you’ll just need to add the following annotation
traefik.ingress.kubernetes.io/router.middlewares: traefik-internal-whitelist@kubernetescrdHTTPS Redirect
To ensure that every connection through a Traefik ingress is HTTPS, we can use a middleware called RedirectScheme. This will upgrade all connections to HTTPS when applied to an ingress.
cat <<EOF | kubectl apply -f -
apiVersion: traefik.containo.us/v1alpha1
kind: Middleware
metadata:
name: redirect-https
namespace: traefik
spec:
redirectScheme:
scheme: https
permanent: true
EOFFor future ingresses, you’ll just need to add the following annotation
traefik.ingress.kubernetes.io/router.middlewares: traefik-redirect-https@kubernetescrd
NOTE: When using more than one middleware, just separate them with commas and use a single annotation. So if we want both HTTPS redirection and the internal whitelist, we would add this annotation.
traefik.ingress.kubernetes.io/router.middlewares: traefik-internal-whitelist@kubernetescrd,traefik-redirect-https@kubernetescrdAccessing the Traefik Dashboard
This dashboard will become useful later on, but for now, know that you can access the Traefik dashboard with this command
kubectl -n traefik port-forward $(kubectl -n traefik get pods --selector "app.kubernetes.io/name=traefik" --output=name) 9000:9000 &Then visit http://localhost:9000/dashboard/#/ from your local machine
Explanation: Certificate Checking in Traefik
Something that I ran into was that many apps & containers like to install themselves with HTTPS by default. They’ll use an auto-generated self-signed cert that isn’t really valid. If we want Traefik to be able to slap a real cert on it, we’ll need to tell Traefik to ignore the self-signed cert of the container so that we can add real certificates, as reverse proxies do.
In the initial installation script, I added this argument to Traefik so that this would not be an issue down the road.
- --serversTransport.insecureSkipVerify=true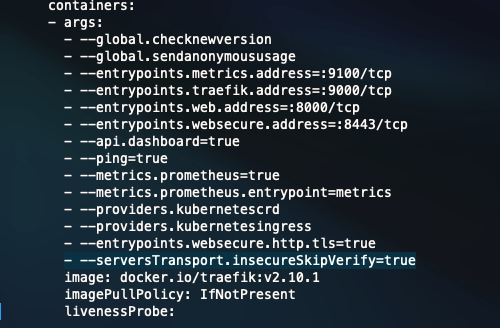
Whenever you need to create an ingress that will point to an HTTPS backend, this is the only annotation you should need to set.
traefik.ingress.kubernetes.io/router.tls: "true"Certificate Management
If you can port-forward on your router, cert-manager can run all your certificate management. This will automate requesting and updating TLS certificates for the cluster.
I’m using Cloudflare as the DNS service for my domain, so these instructions will be different for those who don’t have the pleasure of working with Cloudflare.
Find your API key in the Cloudflare Dashboard. You can get your global API token in the Cloudflare console > User > My Profile > API Keys > Global API Key > View.
NOTE: You can also use an API token, which is more scoped, easily revocable, and therefore more secure.

We’ll first start by creating a secret object that stores out API token for Cloudflare.
# secret-cloudflare.yaml
apiVersion: v1
kind: Secret
metadata:
name: cloudflare-api-key-secret
namespace: cert-manager
type: Opaque
stringData:
api-key: XXXXXXXXXXXXXXXXXXXXXX # change meWe’ll create a ClusterIssuer object in Kubernetes that will automate the signing and creation of certificates for the entire cluster.
- Alternatively, if you wanted to have different Issuers per namespace, you could change the
ClusterIssuerto be just anIssuer. - Make sure to put your email in both locations of this file
- You can use the LetsEncrypt staging server if you’re testing or not using this cluster in production
# clusterissuer-acme.yaml
apiVersion: cert-manager.io/v1
kind: ClusterIssuer
metadata:
name: acme-issuer
spec:
acme:
email: email@email.com # change me
# Configure your server here...
# ---
# Letsencrypt Production
server: https://acme-v02.api.letsencrypt.org/directory
# - or -
# Letsencrypt Staging
# server: https://acme-staging-v02.api.letsencrypt.org/directory
privateKeySecretRef:
name: acme-issuer-account-key
solvers:
- dns01:
cloudflare:
email: email@email.com # change me
apiKeySecretRef:
name: cloudflare-api-key-secret
key: api-keyApply these configuration files
kubectl apply -f ./secret-cloudflare.yaml -f ./clusterissuer-acme.yamlCheck that your clusterissuer is working
❯ kubectl get clusterissuer -o json acme-issuer | jq .status.conditions
[
{
"lastTransitionTime": "2023-07-20T14:55:56Z",
"message": "The ACME account was registered with the ACME server",
"observedGeneration": 2,
"reason": "ACMEAccountRegistered",
"status": "True",
"type": "Ready"
}
]At this point, if you create any ingress in the entire cluster with your domain name, and a certificate will be generated, installed, and can be used.
Testing the Certificate with an Ingress Route
Create a deployment of an echo server instance. It will echo back to you in the webpage to show you all the headers it receives.
# deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: echo-test
spec:
replicas: 1
selector:
matchLabels:
app: echo-test
template:
metadata:
labels:
app: echo-test
spec:
containers:
- name: echo-test
image: fdeantoni/echo-server
ports:
- containerPort: 9000Create a service to point to the pod
# service.yaml
apiVersion: v1
kind: Service
metadata:
name: echo-test
spec:
ports:
- name: http
port: 9000
targetPort: 9000
selector:
app: echo-testCreate an ingress to point to the service
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: echo-test
annotations:
cert-manager.io/cluster-issuer: acme-issuer
traefik.ingress.kubernetes.io/router.middlewares: traefik-internal-whitelist@kubernetescrd # internal only. comment out for external access
spec:
ingressClassName: traefik
rules:
- host: echo-test.<your-domain> # change me
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: echo-test
port:
number: 9000
tls:
- hosts:
- echo-test.<your-domain>
secretName: testing-tlsCertificates are bound to a namespace, so we’ll need to create one certificate for the default namespace
# certificate.yaml
apiVersion: cert-manager.io/v1
kind: Certificate
metadata:
name: testing-tls
spec:
secretName: testing-tls
issuerRef:
name: acme-issuer
kind: ClusterIssuer
dnsNames:
- 'echo-test.<your-domain-name>' # change meApply all of these configuration files
kubectl apply -f deployment.yaml -f service.yaml -f ingress.yaml -f certificate.yamlOnce applied, you should now see a certificate become present
❯ kubectl get certificates
NAME READY SECRET AGE
testing-tls False testing-tls 5sThis will take anywhere from 30 seconds to an hour to create and save a certificate. If the certificate does not say Ready: True in a few minutes, skip to the Debugging Certificate Requests section an ensure no errors are present.
To be able to reach the intended URL, you’ll need to do one of three things
- Create a CNAME on your DNS service provider’s website (externally available)
- Create a DNS entry in your home network’s DNS records (internally available), or
- Edit your local
/etc/hostsfile for local testing (locally available). You could create an entry like this one at the end of/etc/hostsfor local testing
10.0.0.210 test.example.comNow, echo-test should be made available on the domain you’ve entered
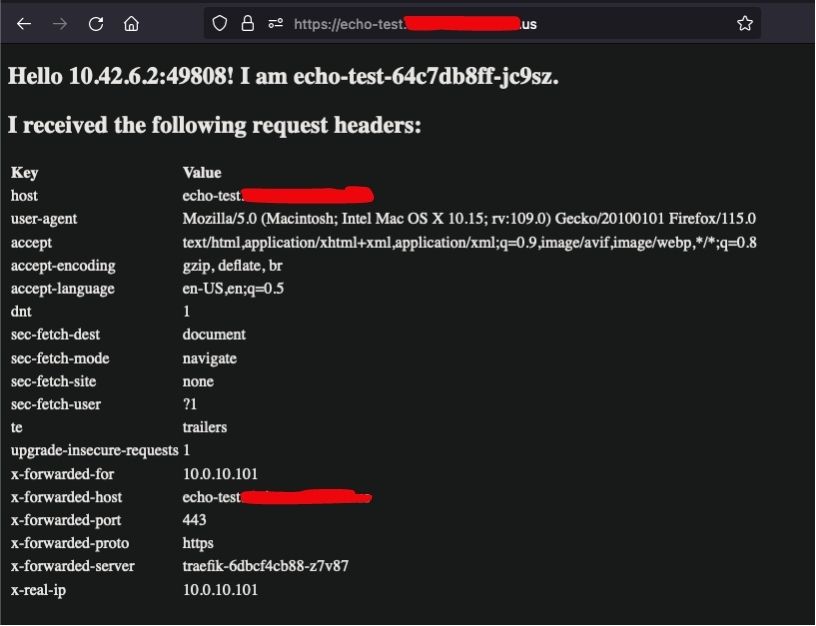
You will want to make sure the x-real-ip and the x-forwarded-for headers are the IP address of your local pc. If this is not the case, traefik‘s load balancing service may still need to be changed to ExternalTrafficPolicy: Local. This may also be the problem if you are forbidden from viewing the page because of the internal-whitelist policy we created.
Debugging Certificate Requests
On the backend, this is creating a certificaterequest object to talk to LetsEncrypt and issue a certificate. You can debug the certificate request process viewing the Events section of the described certificaterequest.
kubectl describe certificaterequest testing-tlsFuture Certificate Generation
In the future, you can slap a LetsEncrypt certificate on any application by following these steps:
- Apply a certificate.yaml to the namespace
- Add
cert-manager.io/clusterissuer: acme-issueras an annotation to an ingress object. - Add your certificate’s name as the
tls.secretNamein your ingress rules
Install Rancher
Rancher Install
Add the helm chart
helm repo add rancher-stable https://releases.rancher.com/server-charts/stableEdit the hostname, then install Rancher. If you don’t want to use LetsEncrypt or if you can’t port-forward, then cert manager won’t work for your domain. If that’s the case, leave off the last two --set lines and optionally try other Helm options.
export RANCHER_HOSTNAME="rancher.example.com"
helm upgrade --install rancher rancher-stable/rancher \
--create-namespace \
--namespace cattle-system \
--set hostname=$RANCHER_HOSTNAME \
--set replicas=3 \
--set ingress.extraAnnotations.'traefik\.ingress\.kubernetes\.io/router\.middlewares'=traefik-internal-whitelist@kubernetescrd \
--set ingress.extraAnnotations.'cert-manager\.io/cluster-issuer'=acme-issuer \
--set ingress.tls.source=secretMonitor the install until its completely rolled out
kubectl -n cattle-system rollout status deploy/rancherUse the following command to get a bootstrap password for logging into Rancher.
kubectl get secret --namespace cattle-system bootstrap-secret -o go-template='{{.data.bootstrapPassword|base64decode}}{{ "\n" }}'Go to the URL of your Rancher instance, input the bootstrap password from earlier, and log in.
Install Longhorn Storage
Now that we have a pretty sweet GUI, we can use it to install Longhorn, a GUI distributed block storage system. This will allow you to have peristent volumes for pods and have them replicate and remain highly available across your entire cluster.
Log into Rancher via the GUI and enter the local cluster
In the bottom left corner, there’s a button titled Cluster Tools
Click Install on the Longhorn App
I like to install this into the System namespace to remind myself I should never mess with it.
Then click Next
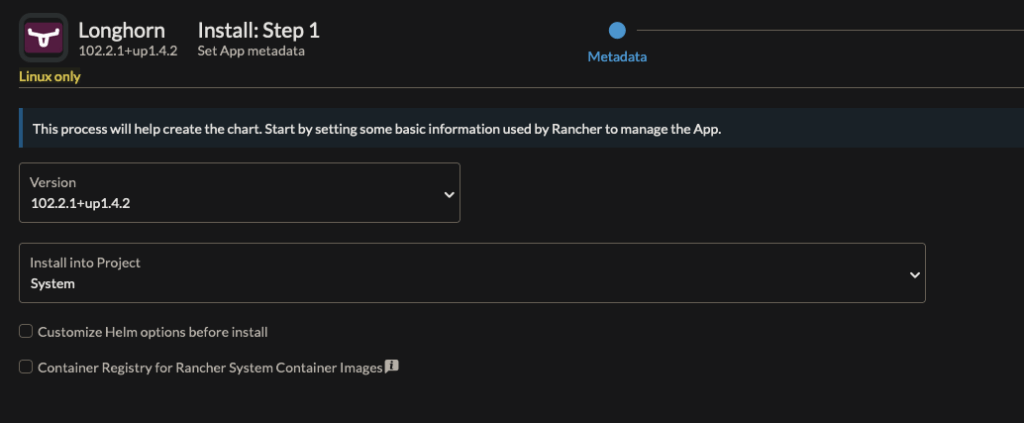
Before clicking Install in the bottom right corner, click through the left-bar settings. I usually make the following changes
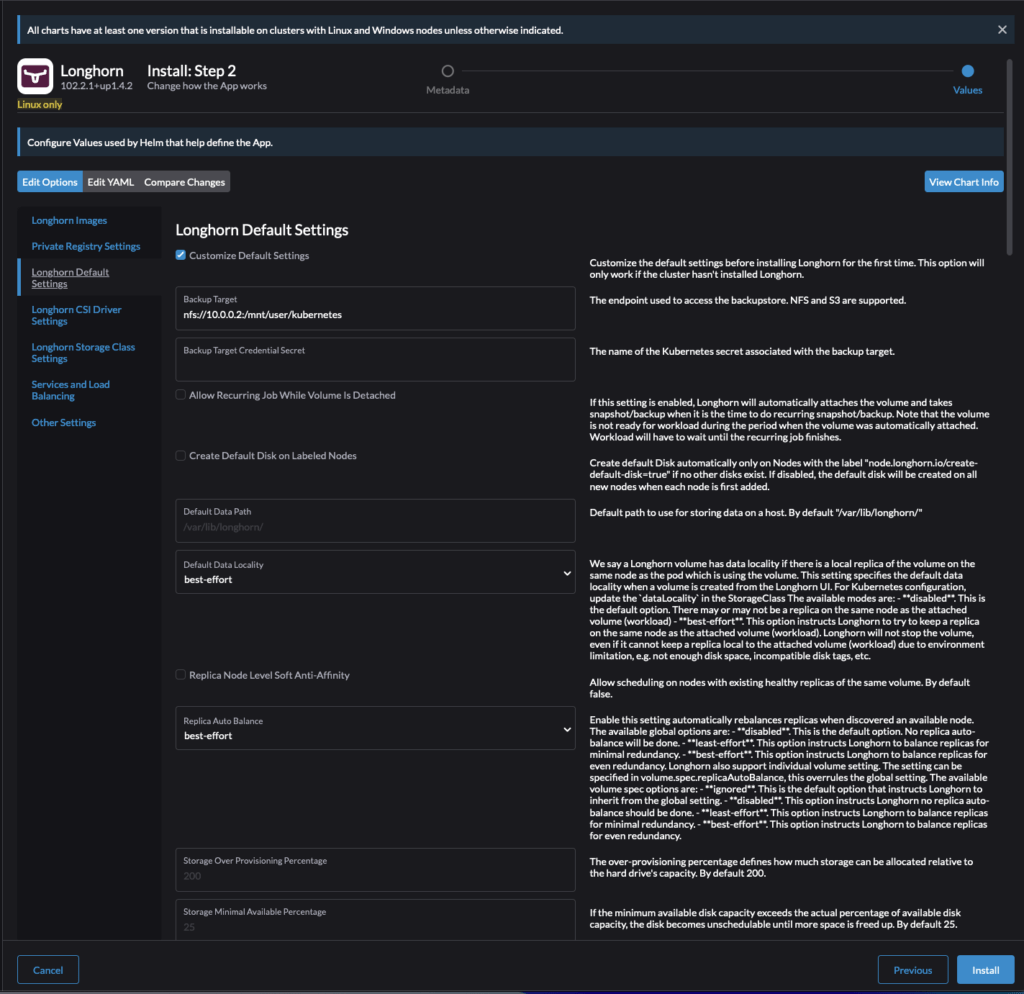
- Longhorn Default Settings
- Customize Default Settings ->
Checked - Backup Target:
nfs://10.0.0.2:/mnt/user/longhorn-backups/- This an NFS share where longhorn puts backups of persistent volumes
- S3 buckets are also supported
- I’ve noticed this feature with NFS is pretty finicky, try not to change it after its set
- Default Data Locality ->
best-effort - Replica Auto Balance ->
best-effort - Default Longhorn Static StorageClass Name ->
longhorn
- Customize Default Settings ->
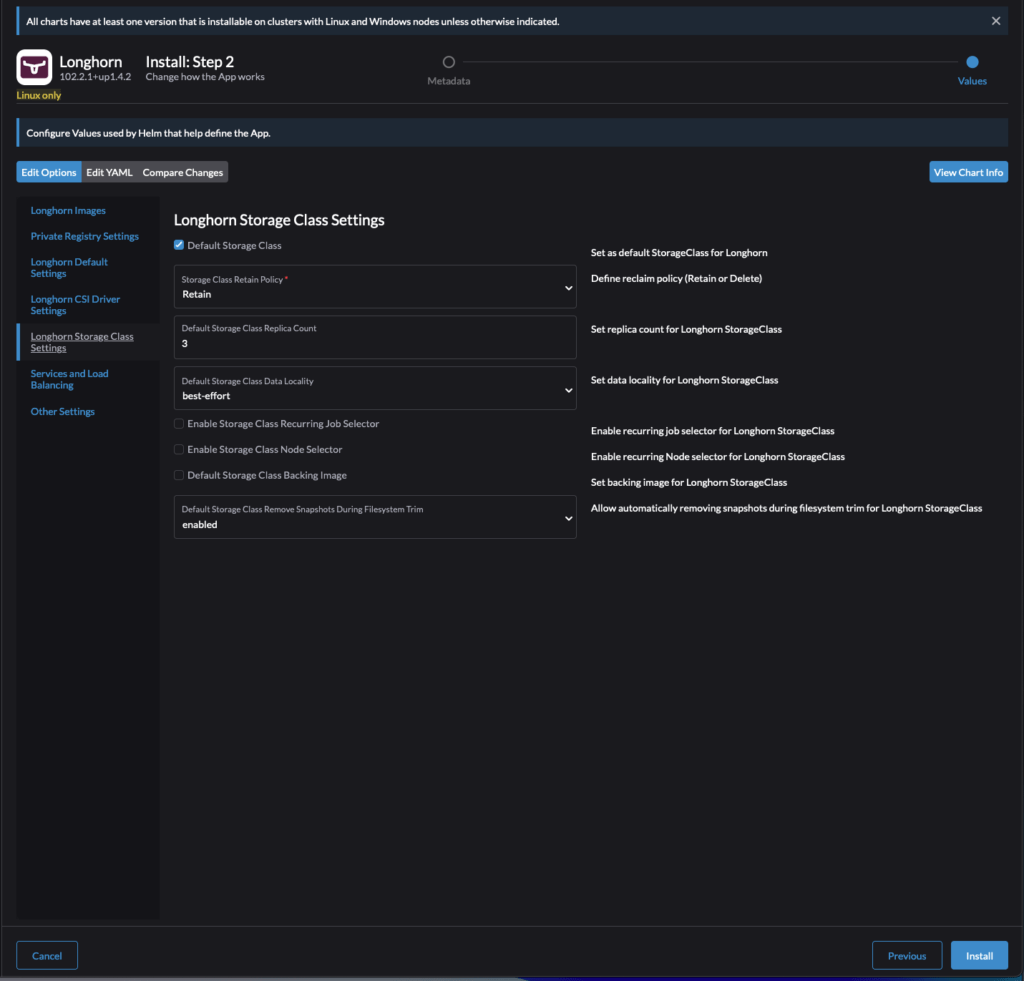
- Longhorn StorageClass Settings
- StorageClass Retain Policy ->
Retain - Default StorageClass Data Locality ->
best-effort - Optional: Enable Storage Class Recurring Job Selector ->
Checked[{"name":"6hourssnap", "isGroup":true},{"name":"dailybackup", "isGroup":true}]- More information on this can be found here
- Default Storage Class Remove Snapshots During Filesystem Trim ->
enabled
- StorageClass Retain Policy ->
Install Longhorn with the blue button
Once its installed, refresh Rancher’s webpage, and there should be a Longhorn tab on the left sidebar.
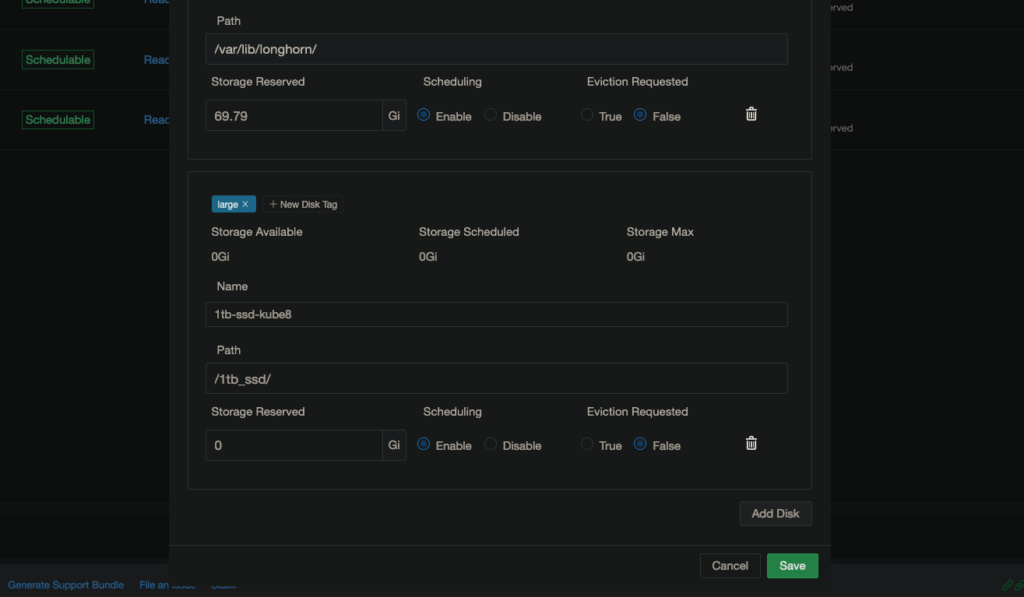
Once in the Longhorn GUI, go to the Nodes tab. You may have to manually add disks via this tab to get Longhorn to use them. For example, I have three 1TB SATA drives scattered in my cluster that I would add now.
NOTE: On the three nodes these drives are on, I mounted them to /1tb_ssd and ensured they would remount there after a reboot.
NOTE: I like to add a large tag to the larger drives so that I can force larger PVs to use those three drives instead of my smaller NVME drives.
Optional: Go to the Recurring Job tab. Here’s the jobs I usually make
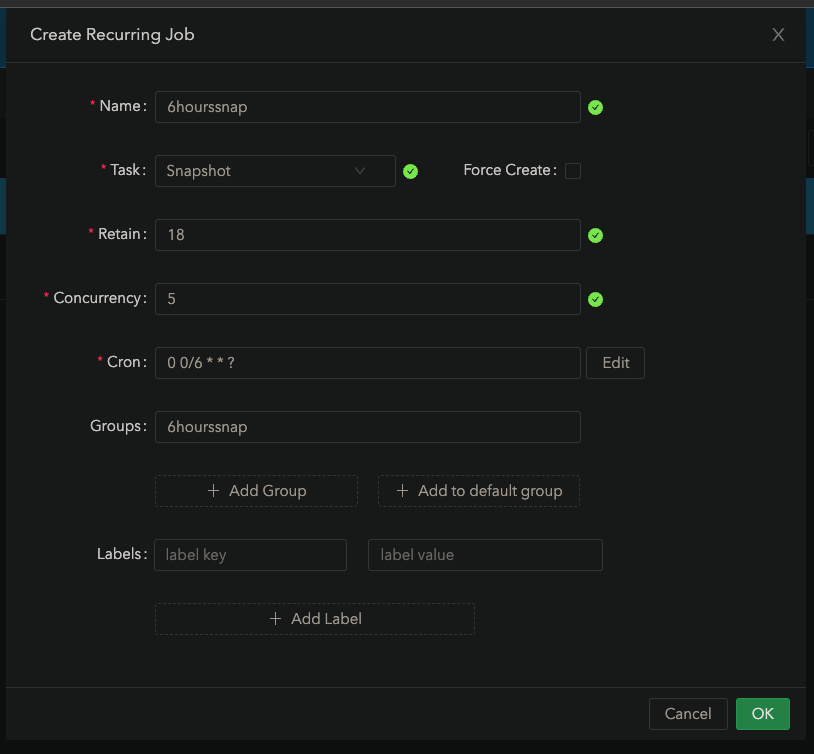
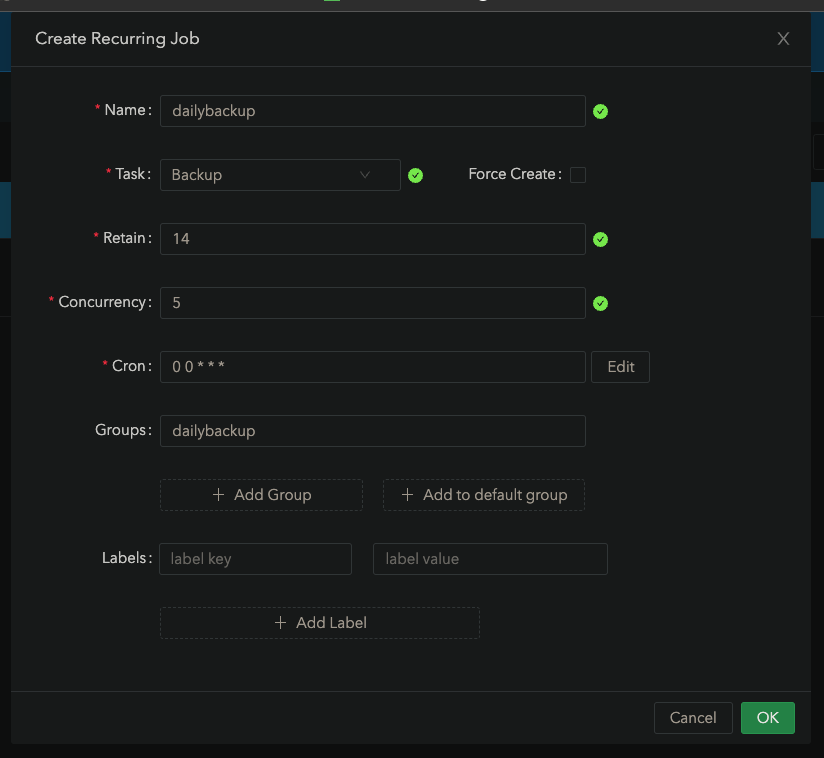
Tip: Before you start diving too deep into Kubernetes, make sure your longhorn backups and restores work!
Optional: Alternative Storage Classes
As mentioned in the Longhorn section, I have different node tags for larger disks. The easiest way I’ve found to assign a PV to a node tag is just by cloning the longhorn storageClass and tweaking its values.
To do this in the Rancher GUI, use the sidebar and go to Storage > StorageClasses.
Clone the longhorn storageClass and save a new version with a different name.
longhorn-large- 3 replicas
diskSelector->large
longhorn-large-one-replica- 1 replica
diskSelector->largerecurringJobs->None- Edit the yaml and remove the
RecurringJobSelector
longhorn-one-replica- 1 replica
diskSelector->NonerecurringJobs->None- Edit the yaml and remove the
RecurringJobSelector
Then, set only the longhorn class to be the default storageClass. You can do this by using the Reset Default option on this page.
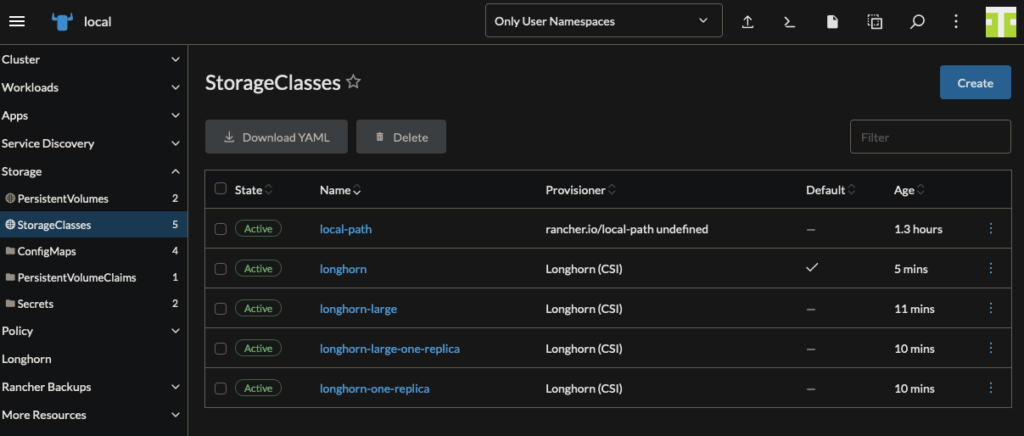
NOTE: You’ll often want to make sure longhorn is the ONLY default storageClass so that it is automatically chosen when new PVs are needed.
Install Argo-CD
Argo-CD is a GUI application that will help a ton when deploying helm charts, especially when visualizing everything.
arkade install argocdArgo-CD does have HTTPS applied by default on their pod’s port. To make connecting an ingress to it easier, we’ll just disable that and use HTTPS externally with Traefik.
kubectl edit configmap -n argocd argocd-cmd-params-cmAdd these two lines to the configmap. Then save and exit
data:
server.insecure: "true"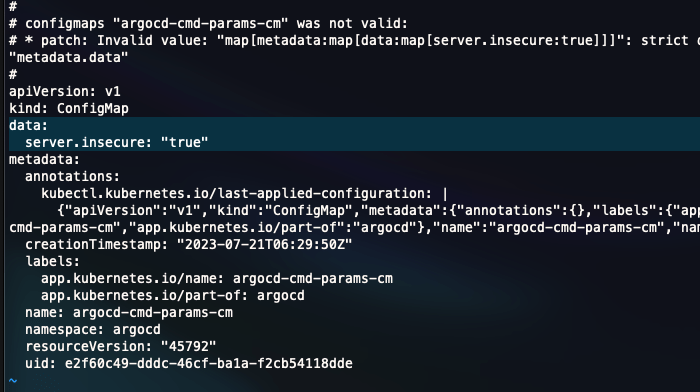
This will take effect after a restart of that pod
kubectl rollout restart deploy argocd-server -n argocdSee if you can set up an ingress route to the argocd-server service (port 80) using what you’ve learned. You can use Rancher’s GUI to do it if you’re not up for more YAML.
Username is admin. The password can be retrieved like so
kubectl get secret argocd-initial-admin-secret \
-n argocd \
-o jsonpath="{.data.password}" | base64 -dOptional: Portainer
Portainer is another GUI application for managing Kubernetes that you may like more than Rancher.
arkade install portainer --namespace portainer --persistenceOptional: Kubernetes Dashboard
Yet another way to visualize your cluster!
These steps are summarized from the k3s website instructions here
GITHUB_URL=https://github.com/kubernetes/dashboard/releases
VERSION_KUBE_DASHBOARD=$(curl -w '%{url_effective}' -I -L -s -S ${GITHUB_URL}/latest -o /dev/null | sed -e 's|.*/||')
kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/$VERSION_KUBE_DASHBOARD/charts/kubernetes-dashboard.yamlIt’s installed, but we need to create a service user to access it. Create two files for this. Here are the contents:
# serviceaccount.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: admin-user
namespace: kubernetes-dashboard# clusterrolebinding.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: admin-user
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: admin-user
namespace: kubernetes-dashboardThen, apply these files
kubectl apply -f ./serviceaccount.yaml -f clusterrolebinding.yamlObtain the bearer token to login
kubectl -n kubernetes-dashboard create token admin-userThe dashboard is set up to use nginx as the ingress controller, not traefik, so the ingress for the dashboard does not work out of the box.
Go into Rancher > Service Discovery > Ingresses and edit the kubernetes-dashboard ingress point. If you don’t see it, make sure kubernetes-dashboard is a selected namespace.
Fix the ports on the dropdown menu to be 8000 and 9000. I also added a hostname and a cert in addition to using localhost.
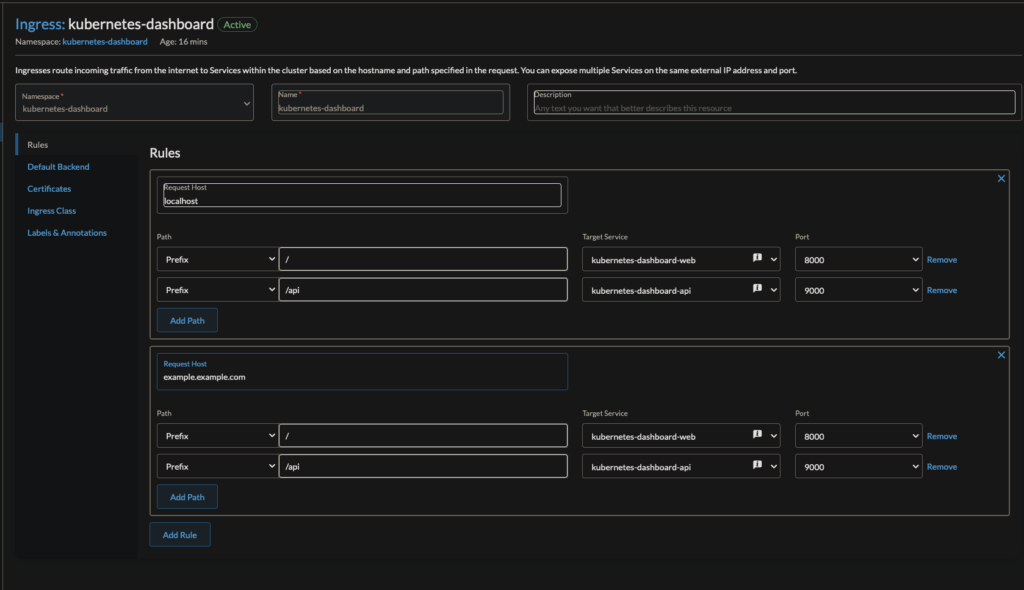
Change the ingressClass to be traefik
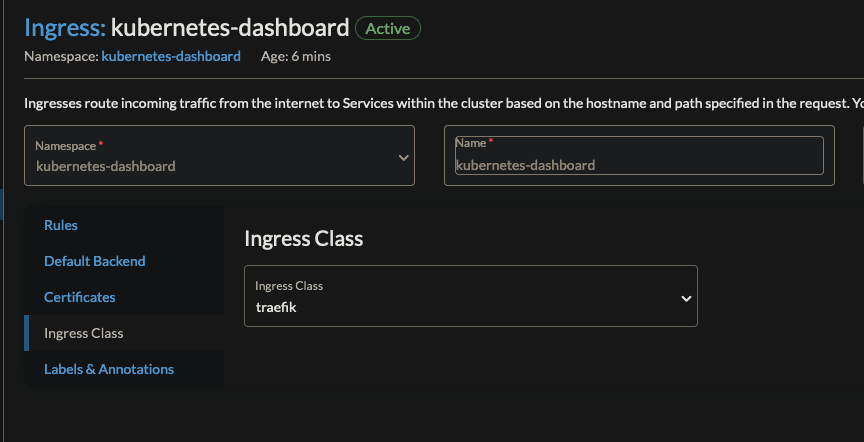
Edit the annotations for traefik to use cert-manager and to ensure this is accessible only internally
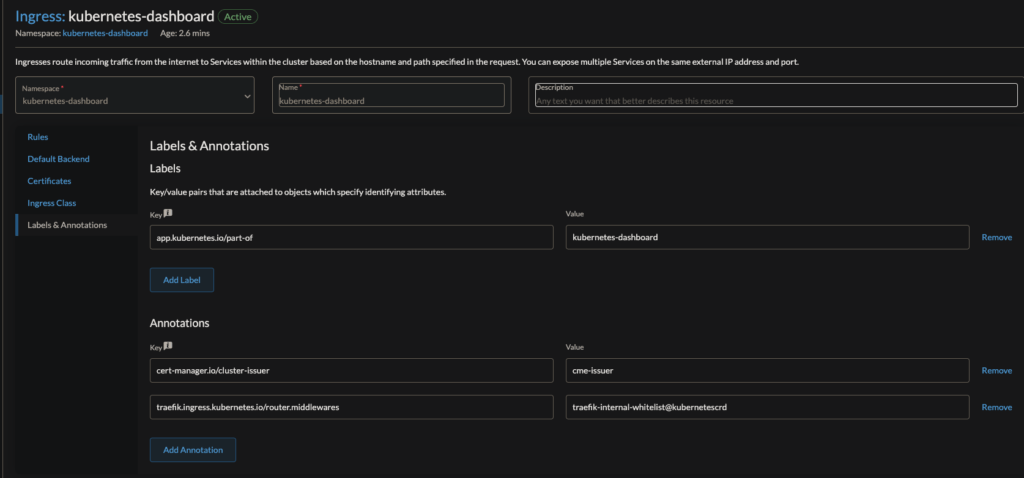
Save the ingress, and the dashboard should be available to you at your hostname
Enter the token from earlier to log in
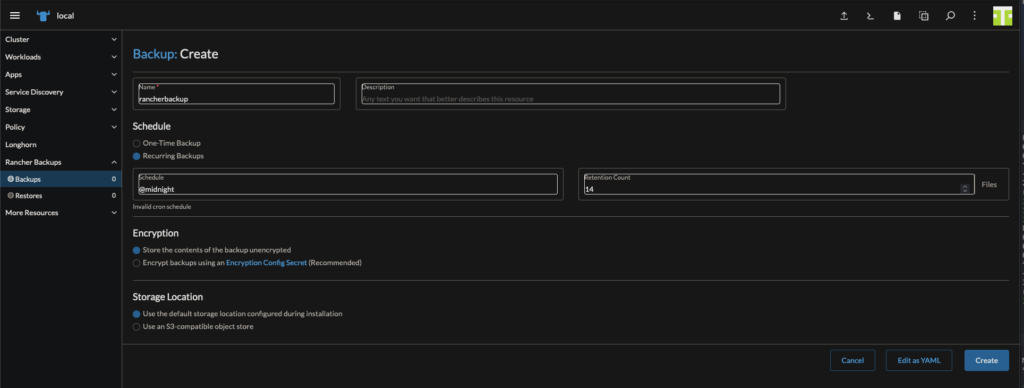
Rancher Backups
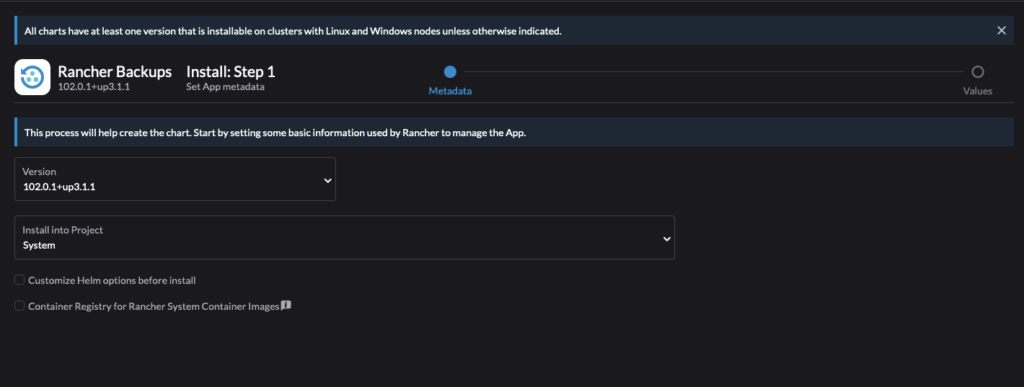
In Rancher, where we just installed Longhorn, install Rancher Backups
I also like to put this in the System namespace
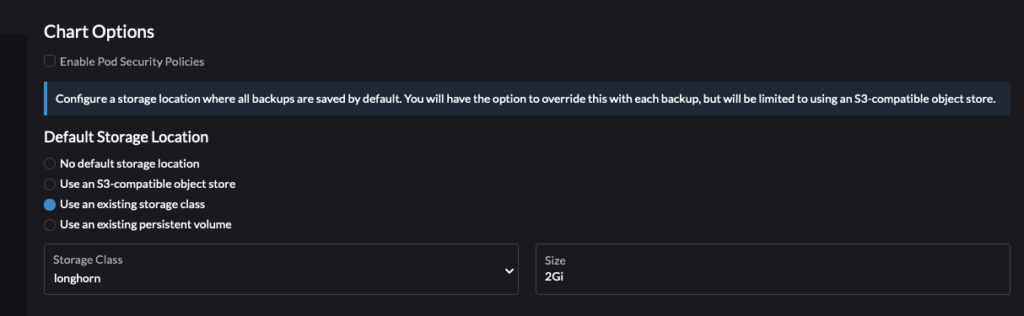
I keep the rancher backups in a PV in longhorn
Once its installed, there’s a Rancher Backups tab in the left side bar
Create a recurring backup job
Graphana + Prometheus Monitoring
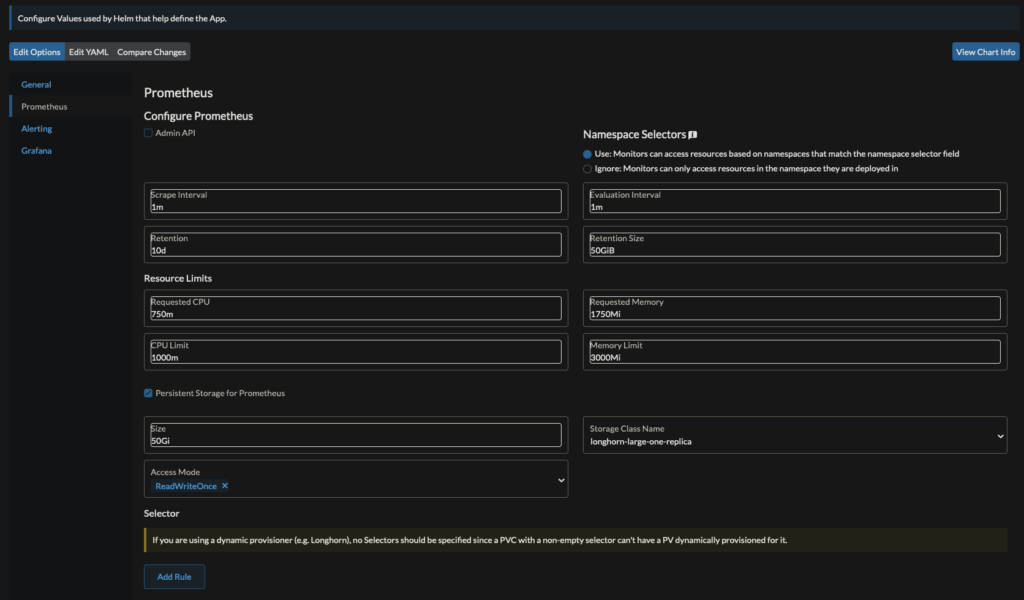
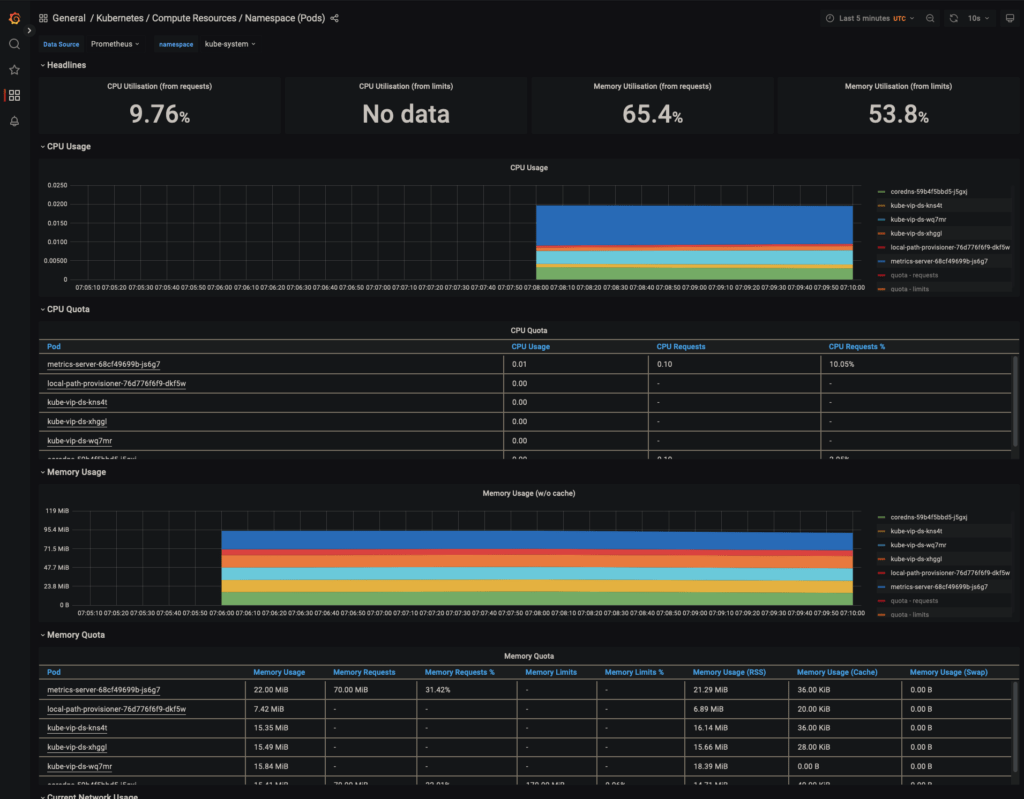
We can gather metrics from our cluster using prometheus and have some sweet graphs and visualizations of these metrics in Graphana – and its all installed for you by Rancher.
Much like Longhorn and Rancher Backups, to go Cluster Tools in the Rancher UI, and install the Monitoring app. If you don’t see yourself deleting it, you can put it in the System namespace to help you not touch it.
You can add peristent storage in Longhorn for both Prometheus and Graphana if you care to preserve monitoring statistics across pod/cluster reboots.
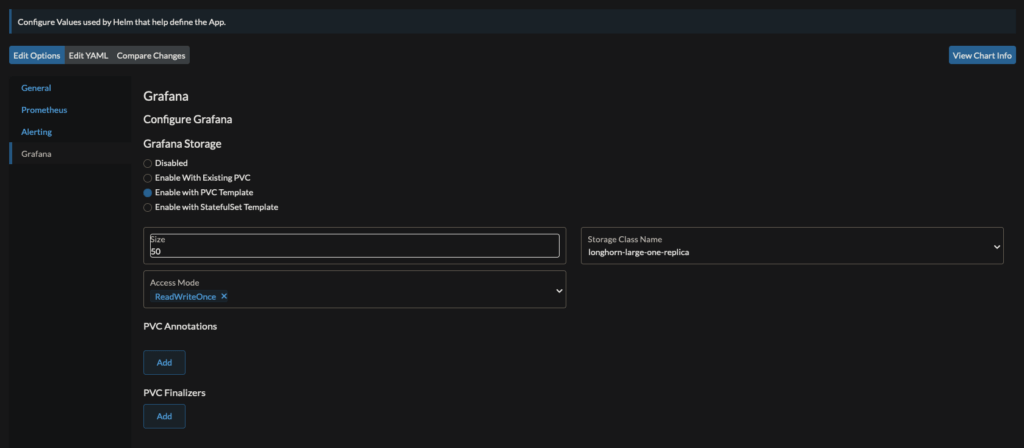
Click install and you’ll have yet another entry in the left-hand sidebar of Rancher. This one is titled Monitoring. Graphana is linked there.
CloudCasa Backups
Enable CSI Snapshot Support
Instructions for this are here, but I’ll summarize. Ensure you’re in the kube-system namespace
kubens kube-systemDownload or clone this github repo
cd ./external-snapshotter
git checkout tags/v5.0.1Delete the Kustomization files (they’re not meant for k3s)
rm ./client/config/crd/kustomization.yaml
rm ./deploy/kubernetes/snapshot-controller/kustomization.yamlApply both folders’ contents
kubectl apply -f ./client/config/crd
kubectl apply -f ./deploy/kubernetes/snapshot-controllerThen, add a default VolumeSnapshotClass
# volumesnapshotclass.yaml
kind: VolumeSnapshotClass
apiVersion: snapshot.storage.k8s.io/v1
metadata:
name: longhorn
driver: driver.longhorn.io
deletionPolicy: DeleteApply it
kubectl apply -f volumesnapshotclass.yamlNOTE: The deletionPolicy could be Retain, but I don’t use CloudCasa for the snapshots as much as I do the copies & yaml backups.
Connect CloudCasa Agent
Create a free account with CloudCasa and log in to https://home.cloudcasa/io
Under Protection > Clusters > Overview , you can Add Cluster
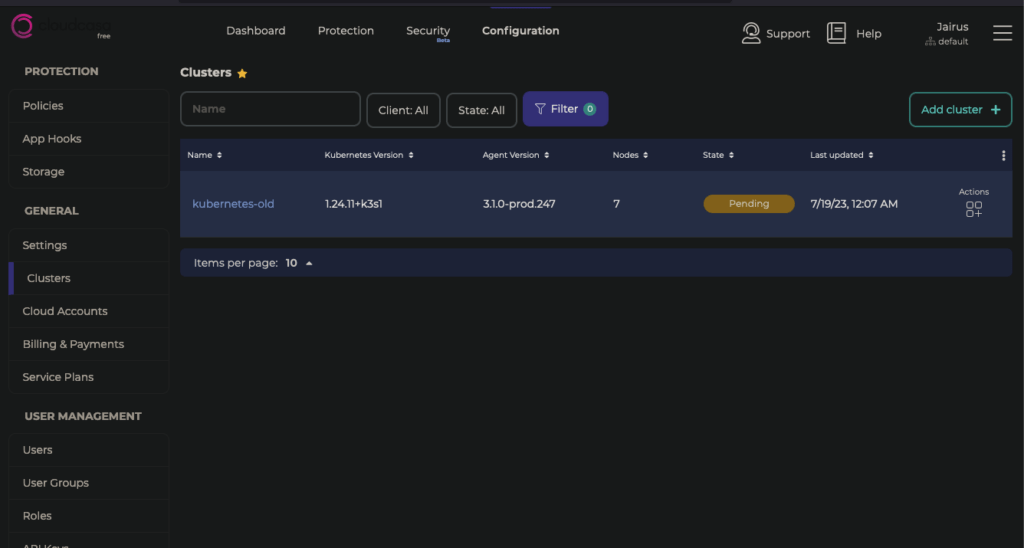
Name the instance what you like and click Register
The web UI will give you a kubectl command to run to connect your cluster to CloudCasa and run their snapshot/backup software. Run the command they gave you.
In the website UI, click Save
Your cluster should soon show up as active in CloudCasa
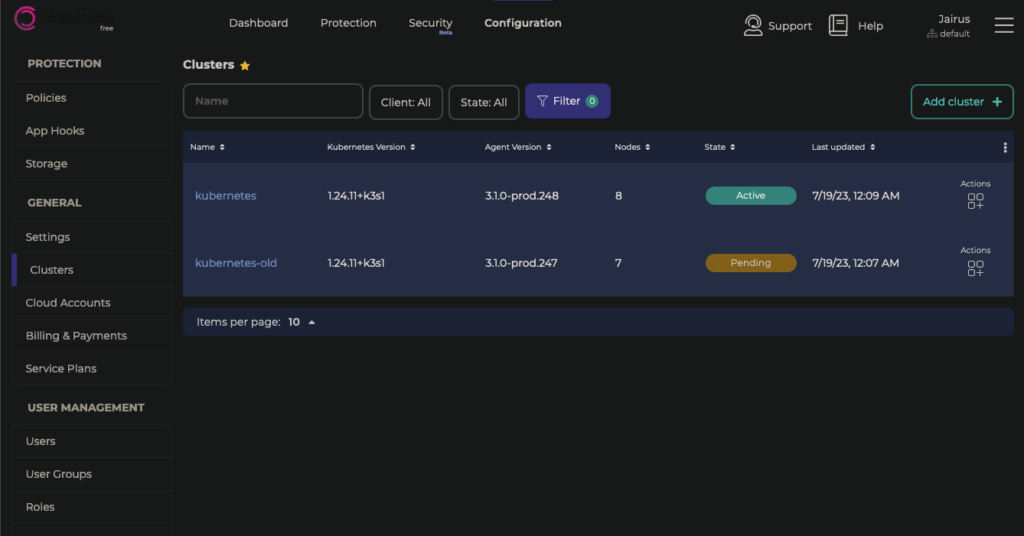
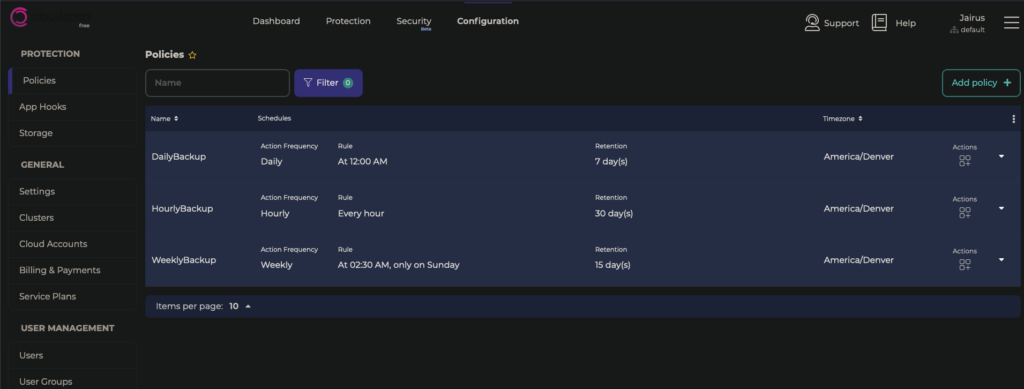
Create Backup Jobs
In the CloudCasa Website UI, select Configuration > Policies > Add Policy. Here are mine
Then, create a backup that uses that policy. Go to Protection > Clusters > Backups and click Define Backup
I’ve created 3 main backups
KubeConfigs, which backs up the entire cluster every hour without the PVs – so just yaml files and manifests- Timing policy is every hour
KubeSnap, which runs snapshot only backuts (does not upload to cloud)- No timing policy because it pretty much does the same things as longhorn snapshots
- Would need to trigger manually
- Excludes namespaces that are dispensible
KubeCopy, which runs copy backing up to the cloud- No timing policy because I don’t want to go over the free plan’s 100GB/month S3 bucket storage
- Would need to trigger manually
- Only specific namespaces are included
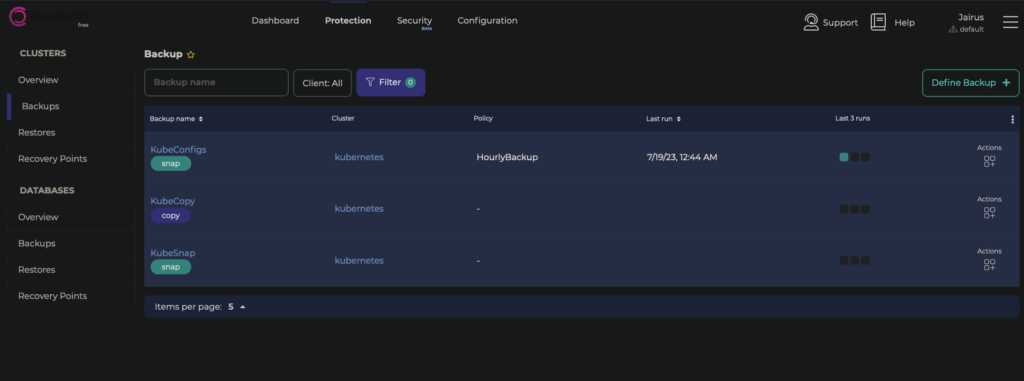
Tip: Ensure that your cloud backups work! I’ve found that restoring the entire cluster doesnt’ work well, but restoring specific namespaces does work well. Try it before you rely on it.
Extra: K3s Uninstall Script
In case you botch your install and need to start over, here’s a script to uninstall k3s from every node and reboot all nodes. I used this many times when making this post, trying to get the install script perfect. So hopefully you shouldn’t need this?
#!/bin/bash
export NODES=(
"kube1" # "10.0.0.201"
"kube2" # "10.0.0.202"
"kube3" # "10.0.0.203"
"kube4" # "10.0.0.204"
"kube5" # "10.0.0.205"
"kube6" # "10.0.0.206"
"kube7" # "10.0.0.207"
"kube8" # "10.0.0.208"
)
export USER="line6"
K3S_UNINSTALL_SCRIPT="/usr/local/bin/k3s-uninstall.sh"
K3S_AGENT_UNINSTALL_SCRIPT="/usr/local/bin/k3s-agent-uninstall.sh"
GREEN='\033[32m'
RED='\033[0;31m'
ENDCOLOR='\033[0m'
for ((i=0; i<3; i++))
do
echo -e "${GREEN}------- Uninstalling k3s from Node ${NODES[i]} -------${ENDCOLOR}"
ssh "$USER@${NODES[i]}" "$K3S_UNINSTALL_SCRIPT"
done
for ((i=3; i<8; i++))
do
echo -e "${GREEN}------- Uninstalling k3s from Node ${NODES[i]} -------${ENDCOLOR}"
ssh "$USER@${NODES[i]}" "$K3S_AGENT_UNINSTALL_SCRIPT"
done
# ____________________________ Reboot all Nodes _____________________________
echo -e "${GREEN}Rebooting all nodes...${ENDCOLOR}"
for NODE in "${NODES[@]}"
do
ssh "$USER@$NODE" "sudo reboot"
done
# _____________________________ Check that all are rebooted __________________________________
# Function to check if SSH connection is successful
check_ssh_connection() {
local node=$1
ssh -q -o BatchMode=yes -o ConnectTimeout=5 "$USER@$node" exit
return $?
}
# Wait for a node to finish rebooting
wait_for_reboot() {
local node=$1
retries=0
max_retries=10
while ! check_ssh_connection "$node"; do
echo -e "Node $node is still rebooting. Retry: $((retries+1))"
sleep 10
((retries++))
if [ "$retries" -ge "$max_retries" ]; then
echo -e "${RED}Timeout: Node $node did not finish rebooting.${ENDCOLOR}"
exit 1
fi
done
echo -e "${GREEN}Node $node has finished rebooting.${ENDCOLOR}"
}
# Iterate over the list of nodes and wait for reboot
for node in "${NODES[@]}"; do
wait_for_reboot "$node"
done

